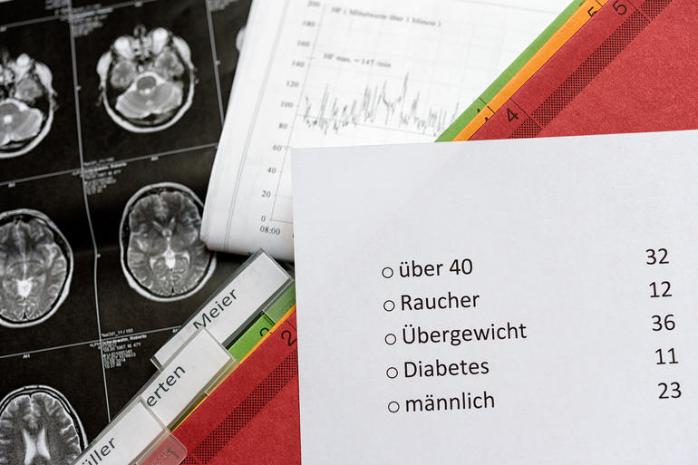
Gesammelte Patientenakten auswerten und dabei keine sensiblen Informationen über einzelne Personen preisgeben: Forscher haben eine Methode entwickelt, die Daten so verrauscht, dass einzelne Personen bei der Analyse anonym bleiben.
Patientenakten sind für Wissenschaftler wertvoll: Sie enthalten potenziell Hinweise, wie man Krankheiten frühzeitig erkennen kann. Doch wie kann man solch gesammelte Daten analysieren und trotzdem die Privatsphäre wahren? Dazu hat das Team um Prof. Hans Simon vom Horst-Görtz-Institut für IT-Sicherheit der Ruhr-Universität Bochum eine Methode entwickelt: Es verrauscht die Daten.
Im Prinzip funktioniert das Verrauschen wie folgt: Für jede Patientenakte wird gewürfelt; die Zahl der Augen wird auf alle Werte in der Akte aufaddiert. Das verändert die einzelnen Daten unvorhersehbar und heftig, macht sich aber im Idealfall bei statistischen Zusammenfassungen nicht stärker bemerkbar als eine ohnehin in den Daten enthaltene Zufallsschwankung.
Für ihre Arbeit haben die Wissenschaftler am Bochumer Lehrstuhl für Mathematik und Informatik zunächst genau definiert, was es mathematisch bedeutet, dass die Patienten anonym bleiben sollen. Und was es heißt, dass die Ergebnisse mit und ohne Verrauschen ähnlich sein sollen. Um die definierten Anforderungen zu erfüllen, übersetzten die Mathematiker das Problem in eine geometrische Darstellung.
Jede Patientenakte repräsentierten sie als Vektor, also als einen Pfeil in einem geometrischen Raum. Der Auswertalgorithmus durfte nur Ja/Nein-Fragen stellen, etwa: Ist der Patient Raucher? Ist der Patient schwerer als 80 Kilogramm? Auch jede dieser Fragen stellten die Mathematiker als Vektor dar. Bildeten die Vektoren für Akte und Frage einen stumpfen Winkel, symbolisierte das eine Nein-Antwort; ein spitzer Winkel stand für eine Ja-Antwort.
Die Wissenschaftler verrauschten dann nicht mehr die Originaldaten, sondern führten diesen Schritt erst aus, nachdem sie die Daten in Vektoren umgewandelt hatten. Das erlaubte es ihnen, Informationen über einzelne Patienten anonym zu halten, aber trotzdem statistische Aussagen über die gesammelten Daten aller Patienten zu treffen. Die selbstständig lernenden Computerprogramme konnten in den veränderten Daten ähnlich gut Zusammenhänge aufdecken wie in den Originaldaten.
Weitere Informationen: Beitrag im Wissenschaftsmagazin Rubin
Unsere Whitepaper-Empfehlung

Teilen:





{kind=link}